Yapay zeka dünyasında küresel çapta yaşanan gelişmeler, artık yerel çözümlerin de önünü açıyor. Türkiye merkezli yazılım şirketi VNGRS, sıfırdan Türkçe için geliştirilen ilk büyük dil modeli olan Kumru LLM’i tanıtarak bu alanda büyük bir adım attı. Hem teknolojik hem stratejik olarak dikkat çeken Kumru, Türkçe doğal dil işleme alanında yeni bir sayfa açıyor. Peki, İlk Türkçe büyük dil modeli Kumru nedir, nasıl kullanılır, özellikleri neler? Yerli yapay zeka Kumru ücretli mi, fiyatı ne kadar? İlk yerli yapay zeka Kumru’ya dair merak edilen tüm detaylar haberimizde…
İLK TÜRKÇE BÜYÜK DİL MODELİ KUMRU NEDİR?
Kumru, Türkiye’nin ilk yerli büyük dil modeli (LLM – Large Language Model) olma özelliği taşıyor. VNGRS tarafından geliştirilen bu model, 7.4 milyar parametreye sahip ve yalnızca Türkçe verilerle sıfırdan eğitilmiş durumda. Bu yönüyle, diğer çok dilli modellerin aksine Türkçeye özgü dil yapısı, ekleri, sözdizimi ve anlam ilişkilerini çok daha derinlemesine kavrayabiliyor.
Modelin mimarisi açık kaynaklı Mistral-v0.3 tabanlı olarak inşa edilmiş. Kumru’nun geliştirilme sürecinde LLaMA-3 teknik dökümanları da rehber olarak kullanılmış. Bu da modeli, güncel dil modeli mimarilerinin mantıksal derinliğiyle birleştiren hibrit bir yapıya kavuşturmuş.
Eğitimi Nasıl Yapıldı?
Modelin ön eğitimi 45 gün sürdü. Bu süreçte NVIDIA H100 ve H200 GPU’ları kullanıldı ve yaklaşık 500 GB’lık temizlenmiş, yinelenmemiş Türkçe veriyle model sıfırdan eğitildi. Sonrasında ise 1 milyon örnekten oluşan veri setiyle fine-tuning (ince ayar) işlemi yapıldı. Bu örnekler; belge özetleme, soru-cevap, dilbilgisi düzeltme gibi birçok görev türünden oluşuyordu.
TÜRKÇE BÜYÜK DİL MODELİ NASIL KULLANILIR?
Kumru LLM’in kullanım alanları oldukça geniş. Başta belge işleme, metin özetleme, soru-cevap sistemleri, bilgi çıkarımı, içerik üretimi ve dil düzeltme olmak üzere, çok sayıda doğal dil işleme (NLP) görevini yerine getirebiliyor. Bu da modeli hem kamu kurumları hem de özel sektör için değerli bir yapay zeka aracı haline getiriyor.
Teknik Yeterlilik ve Donanım Gereksinimi
Kumru, verimlilik odaklı bir şekilde optimize edildiği için RTX 3090 veya RTX A4000 gibi 16 GB VRAM’e sahip GPU’larda sorunsuz şekilde çalışabiliyor. Bu, özellikle kurum içi konuşlandırma (on-prem deployment) yapmak isteyen firmalar için ciddi bir avantaj sunuyor.
Ayrıca model, 8.192 token’lık bağlam uzunluğu destekliyor. Bu da yaklaşık 20 A4 sayfası kadar metni tek seferde analiz edebileceği anlamına geliyor. Modelin, giriş-çıkış süreçlerinde RegEx tabanlı özel tokenizasyon sistemi kullanması da verimliliğini artırıyor. Türkçeye özel bu sistem, satır sonlarını, noktalama işaretlerini ve sayıları ayrı token’lar halinde işliyor. Böylece aynı metin, daha az kaynakla işlenebiliyor.

TÜRKÇE BÜYÜK DİL MODELİ ÖZELLİKLERİ NELER?
Kumru’nun öne çıkan özellikleri şunlardır:
Türkçeye özel sıfırdan eğitim: Çok dilli modellerin aksine yalnızca Türkçeye odaklanarak dilin inceliklerini daha iyi kavrar.
Yüksek bağlam kapasitesi: 8.192 token bağlam uzunluğu ile uzun metinleri eksiksiz işleyebilir.
Hafif model tasarımı: 7.4 milyar parametreye sahip olmasına rağmen optimize edilmiş yapısı sayesinde orta düzey donanımlarda çalışabilir.
Özel tokenizasyon sistemi: Türkçe için geliştirilen RegEx tabanlı işlemci sayesinde daha az token kullanımı sağlar.
İngilizce ve kod anlama yeteneği: Eğitimde Türkçeye odaklanılsa da model, İngilizce dilini ve kodlama dillerini de tanır.
Kuruma özel uyarlanabilirlik: VNGRS, farklı sektörler için fine-tuning ile özelleştirme hizmeti sunmayı planlıyor.
Performans Karşılaştırması
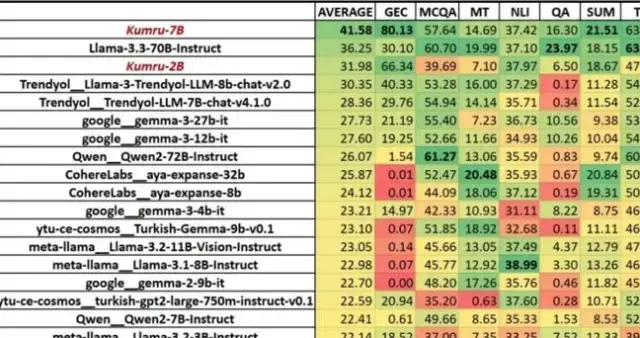
Yapılan testlerde Kumru, LLaMA-3–70B, Gemma-3–27B, Qwen-2–72B ve Aya-32B gibi daha büyük parametreli modelleri Türkçe özel görevlerde geride bıraktı. Özellikle özetleme ve dilbilgisi düzeltme gibi Türkçe dil yapısına duyarlı görevlerde öne çıkıyor.
TÜRKÇE BÜYÜK DİL MODELİ KUMRU ÜCRETLİ Mİ, FİYATI EN KADAR?
Kumru şu anda doğrudan açık kaynak olarak sunulmuyor. Ancak, VNGRS modeli lisanslama ve kurum içi konuşlandırma esasına dayalı olarak ücretli şekilde sunuyor. Yani bireysel kullanıcılardan ziyade, modelin hedef kitlesi öncelikle kurumlar ve büyük işletmeler.
VNGRS’nin hedefi, modeli kurumların kendi sunucularına entegre ederek veri güvenliği ve özel kullanım senaryoları açısından tam kontrol sağlayabilmek. Bu yapı, özellikle finans, sağlık, hukuk ve kamu gibi veri hassasiyetinin yüksek olduğu alanlarda ciddi bir avantaj sağlıyor.